李宏毅老师以openclaw为例解读ai agent运行原理
1.基本介绍
李宏毅老师讲解openclaw的视频地址:
https://www.youtube.com/watch?v=2rcJdFuNbZQ
https://www.bilibili.com/video/BV1oqcrzwEBV/?spm_id_from=333.1365.list.card_archive.click&vd_source=a432cb5e896a2b96961d1f73a6ebe0ca
上课的PPT下载:https://speech.ee.ntu.edu.tw/~hylee/ml/ml2026-course-data/intro.pdf
有一部电影的名字叫做《我的失忆女友》,里面的两个人物是大壮和小美。小美每一天早上起来的时候,都记不得之前发生的事情,所以大壮需要写日记,每天早上都要去给小美看,让小美回忆起昨天发生了什么。就像大壮一直追、一直追,最后终于追到了小美。
其实 AI 技能也是这样的,只有在一个对话聊天窗口里面,它才可以记得上下文的内容。而且它的记忆窗口是有限制的,当你新开一个窗口的时候,就好像小美第二天早上醒来一样,它就失忆了。AI 也不记得之前发生了什么事情,所以就需要你把之前发生的事情告诉它。
2.记忆检索功能
下面的这个就是 OpenClaw 的记忆检索工作流程,也就是我们之前所提到的,它是如何从存好的记忆里面找到我们想要的内容。
我们可以发现,在左边的这个里面,实际上就是 memory 文件夹和 mermaid 这些文字文件。它们被切分成了一小块一小块的,每一块就叫做一个 chunk(数据块)。
这些存储好的记忆块,会根据语言模型下达的指令进行检索。例如,用关键词“YouTube 影片”搜索记忆,OpenClaw 就会把关键词“YouTube 影片”和每一个 chunk 做两种相似度比对:
S1 字面比对
它比较的是关键词出现的次数和字面值。S2 语义比对
它会转换成向量(Embedding)嵌入,计算两个向量的余弦相似度。余弦相似度越高,S2 的分数就越高。
最后通过公式 $S = A \times S1 + B \times S2$,把字面分数和语义相似的分数相结合,计算出最终的相似度分数,然后把分数最高的 Top-K 个 chunk 传递给大语言模型。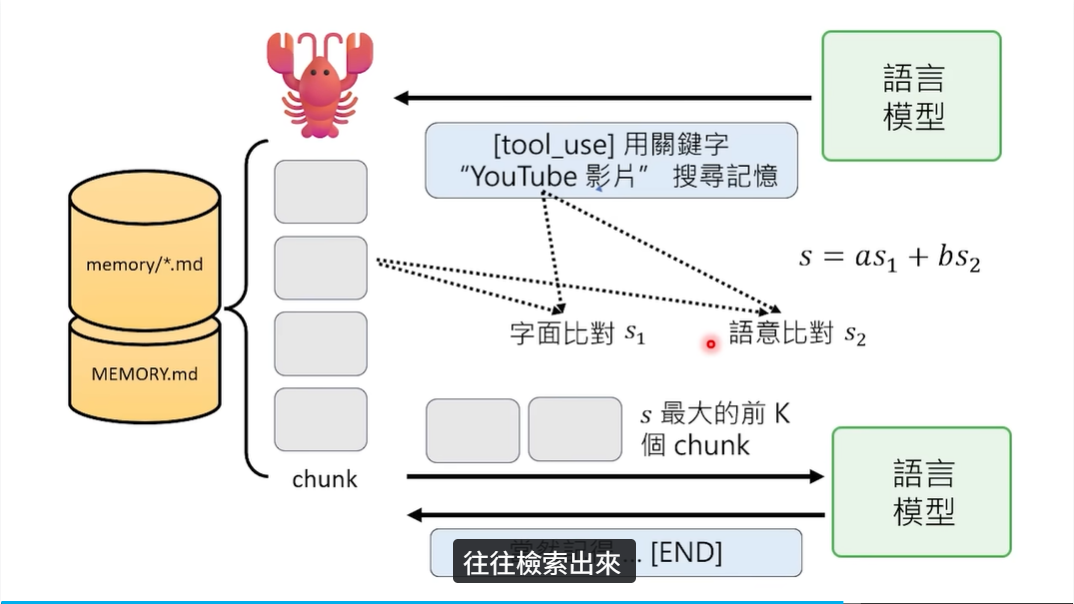
其实基本的流程如下:
- 人发起问题。
- OpenClaw 把人的问题进行预处理,即把问题和系统提示词进行二次整理,传递给大语言模型。
- 大语言模型看到问题后,可能需要调用搜索引擎工具才能回答,于是将其传递回 OpenClaw。
- OpenClaw 执行搜索,进行切块(chunk)划分,并计算相似度分数。
- 最终把相似度最高的前 K 个分数的结果返回给大语言模型。
- 大语言模型基于返回的内容整理出回答,然后再反馈给人类。
3.心跳机制
下面这个就是小龙虾的心跳机制,其实和普通大模型有类似的地方。
当你发给它一段提示词,它回答你之后,首先会把你的提示词给语言模型,语言模型返回一段内容,然后它再把这些东西发给你。
这个时候,如果你没有任何问题,小龙虾和语言模型之间就没有交互了。心跳机制说的就是,小龙虾每隔一段时间都要去“戳一戳”这个语言模型,看看它有没有什么任务要完成。
如果没有任务的话,那肯定就不需要执行。它会去阅读一下这个 habit.md 文件,看看是否有一些存在的定时任务,然后就可以去执行了。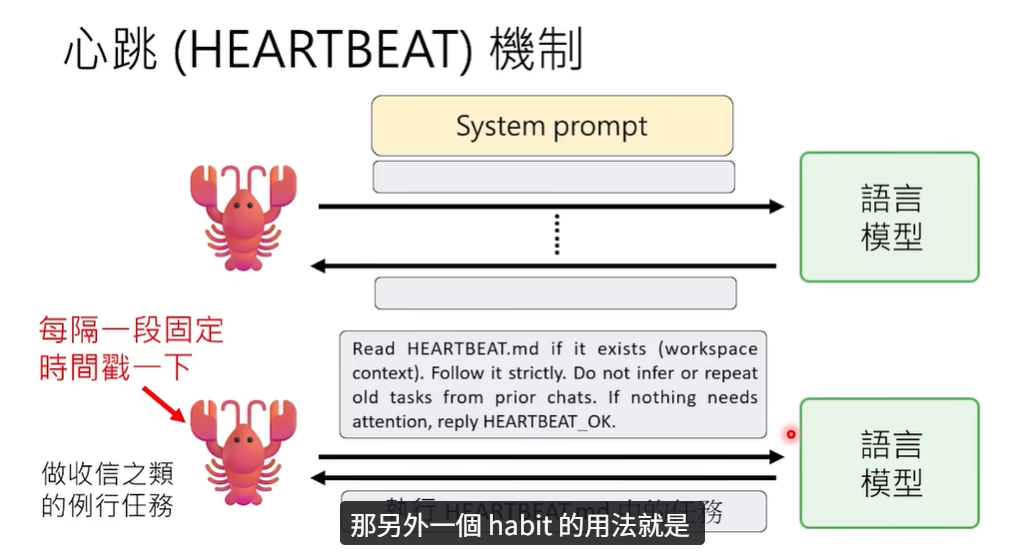
4.排程系统
接下来我们介绍一下 OpenClaw 的这个“等待问题”的例子,核心是想说明 AI 现在是怎么学会等待的。
我们顺着流程走一遍。比如说我们现在给 OpenClaw 发送信息,让它使用 NotebookLM 生成幻灯片。它收到我们的请求之后,其本身是一个写死的规则,并没有智能,所有的决策都是靠后面连接的大语言模型来完成的。
所以它并不是一个模型,而是一个调用大语言模型的 Agent 型框架,本身不具备大模型的能力。整个过程如下:
任务分析与发送
当 OpenClaw 收到我们的请求后,会首先把请求发送给大模型。大模型进行分析后,再告诉 OpenClaw 应该去做什么。执行初步指令
OpenClaw 意识到它需要先打开网页,然后上传文件。得到的结果是“幻灯片正在生成”。状态返回与工具调用
大模型收到了“正在生成”的状态。由于此时无法进行下一步,聪明的大模型给 OpenClaw 下发了一个工具指令,让它设置一个定时任务,三分钟之后再来检查网页的状态。定时任务排程
这就是定时任务排程工具的使用,它能帮助大模型“定好闹钟”,到点再继续操作。任务触发与完成
三分钟之后,OpenClaw 按照时钟触发了任务,把检查到的 NotebookLM 状态指令再次传递给大模型。大模型发现下载已经完成,于是就让它打开网页,下载完成的幻灯片。
最终,通过这种方式完成了整个任务。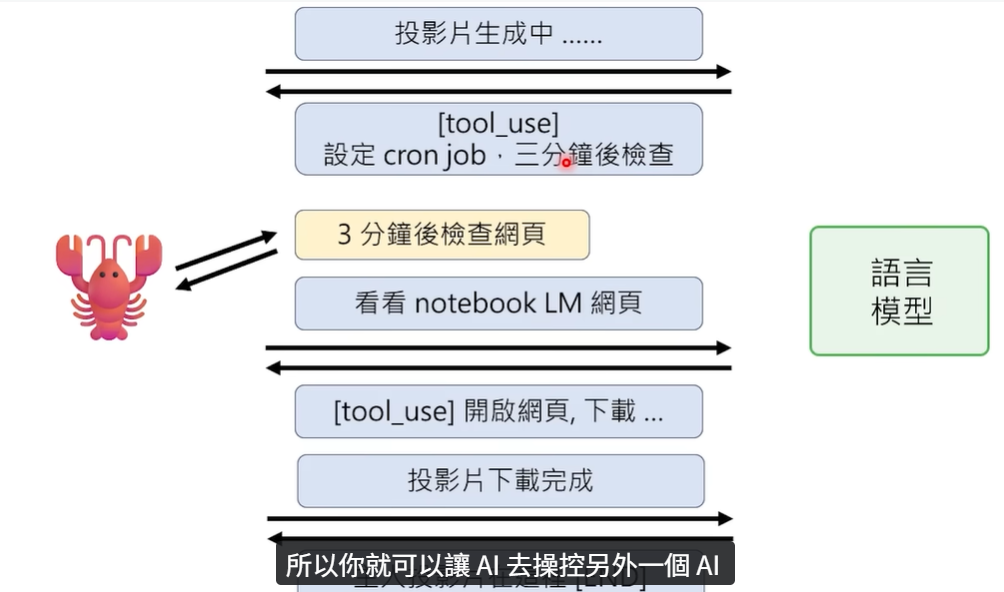
5.上下文压缩机制
大语言模型的输入长度是有限的。OpenClaw 运行时间越长,积累的对话历史就越多,拼出来的 Prompt 也就越长,总有一天会超出大语言模型的长度限制。
所以这个压缩机制就是解决这个问题的:
- 当 OpenClaw 积累了太多的历史对话,整体长度超过阈值之后,它会把旧的历史对话单独提取出来,传递给大语言模型。
- 让大语言模型把旧的对话浓缩成一段简短的摘要。
这样可以更好地进行上下文的压缩,防止拼接之后的 Prompt 过长,超出大语言模型的长度限制。这个压缩其实就是解决上下文在长度上的问题的。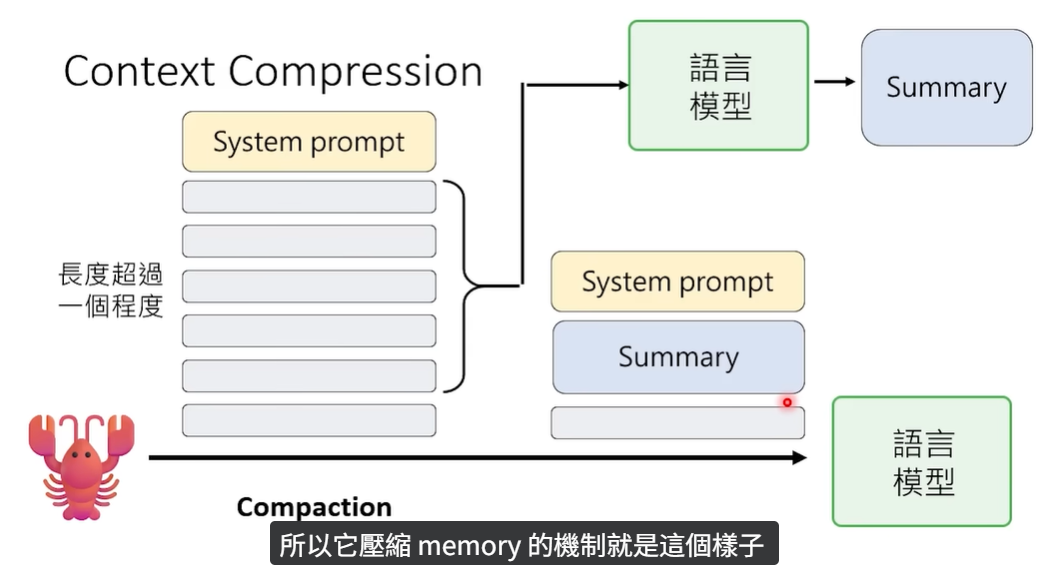
6.sub-agent(子代理)
接下来我们介绍一下 OpenClaw 一个很巧妙的工具,就是 Sub-agent(子代理)。
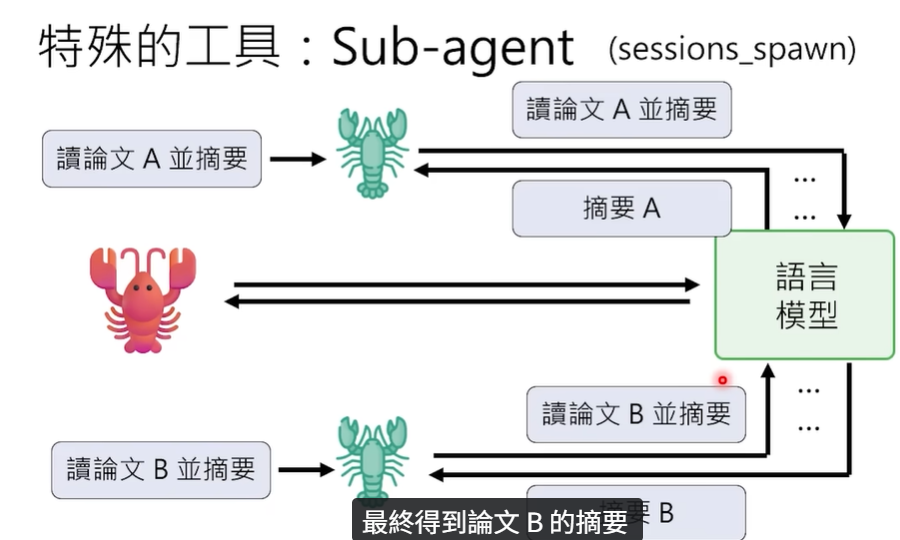
子代理主要用来解决大任务在分析时占用过多上下文的问题。假设用户给 OpenClaw(也就是大家常说的小龙虾)布置了一个任务:“给我把这 80 篇论文全部做完摘要,然后整理一份总结。”
如果让主代理一篇一篇地做,每一篇都要占用上下文,很快就会把上下文空间占满。通过 Sub-agent 的机制,主代理只要把任务传递给大语言模型,模型会决策并将其拆分成多个子任务。每个子任务都会生成一个全新的、绿色的“小龙虾”,也就是一个 Sub-agent。
具体流程如下:
- 第一个子任务是阅读论文 A 并做摘要。任务交给第一个子代理,它独立与大模型交互完成任务。
- 完成后,子代理将论文 A 的摘要返回给主代理,然后这个子代理就自动销毁了,不占用任何主代理的上下文空间。
- 第二个子任务是阅读论文 B 并做摘要。系统会生成第二个新的子代理,重复上述过程:完成摘要、返回结果给主代理、随后销毁。
以此类推,直到所有子任务全部完成。主代理拿到了所有子代理返回的摘要,再把这些内容发送给大模型,由大模型整理成最终的总结结果返回给 OpenClaw,最后由 OpenClaw 返回给用户。
为什么要这么麻烦地生成子代理,而不是让主代理一遍一遍地做呢?主要是因为子代理在任务完成后就会被销毁,这样就不会持续占用主代理的上下文空间,从而避免长度超出上下文限制。这在本质上也是一种高效的上下文管理方式。