首发少数派:https://sspai.com/post/107197第一次参加 少数派 的年度征文活动,2025 年 8 月,我加入了少数派,作为一名内容创作者,我开始发布了自己的一些文章。
最开始,我是在公众号上关注了一个 ID 叫做“西郊次生林”的博主。我是在这个博主的文章里了解到的 Obsidian非常不错的玩法,他主要更新一些 Obsidian 相关的文章,对软件的使用非常熟悉。
也是通过他的文章,我了解到了少数派这个社区平台,并选择加入。
在 2025 年的最后一天,实际上我已经写好了自己的年度总结。
当少数派的年度征文发布这个活动的时候,我并没有打算去参与。但是直到前些日子的一天,我在少数派的 Telegram 群聊里面看到了这篇文章,感觉还是非常有感触的。
所以,阅读完这篇文章之后,我又有了想写下属于自己 2025 的一种冲动。
今年少数派的年度征文分为了人工赛道和 AI 赛道。其实我觉得选择哪个赛道并无所谓,只要能写出让大家有收获的文章或者作品就可以。
我也非常羡慕那些能够使用 AI 写出非常棒的文章的博主,但我深知自己使用 AI 没有办法达到那种水平。因为我使用 AI 写的文章,AI 味都非常的浓,所以我日常的创作更多的是手工创作。
因为我自己是一名高校的学生,所以在 2025 年最后一天的年度总结里面,主要聚焦的是学校和生活相关的主题。
那么少数派的年度征文肯定要写点不一样的。而且 2026 年已经过去了两个多月,所以肯定有些新的心得。
在这篇年度征文里面,我准备围绕 AI发展,AI产品/工具 和知识管理(内容创作)这几个伴随我学习成长的核心,聊一聊我的看法、经历和思考。
【写在前面】 本文篇幅较长,行文可能稍显零散,但字字句句皆为最真实的个人经历与深度思考。 使用typeless完成本文,感谢你愿意花时间停留在这些文字上,希望能为你带来一些有价值的参考和启发。
文章里面推荐了一些自己正在订阅使用,觉得不错的AI产品&工具,非广告,真心推荐,没有任何利益关系
1.关于AI
可以说,我的大学生活伴随着 AI 的高速发展。
作为一名“小镇做题家”,在没上大学之前,我更多的是沉溺在书山题海中,对于外面的世界并不了解。上大学后环境相对自由,我才真正见证了 AI 的这段发展历程,对我而言,那是刻骨铭心的。
我刚刚上大学的时候,流行的还是百度的文心一言(后来改名叫做文小言)。当时的百度利用自己在搜索和数据方面的积累优势,打造了国内首个 AI 大模型。
在当时的版本中,百度属于国内 AI 模型的领跑者。而如今,大模型领域已是逐鹿相争、群雄并起,现在的百度早已不再是当年的百度了。
2024年是低调发展的一年,接下来就是2025年——AI 全面开发、全面开花、全面爆发的一年。
从2025年1月份 DeepSeek 横空出世,就打响了中国 AI 赶超的第一枪,给了西方国家当头一棒。
然后就是阿里的通义千问、字节的豆包、腾讯的元宝,各个大厂分别推出了自己的模型。
对话聊天模型这个圈子,开始变得逐渐热闹起来。从 DeepSeek 发布开始,我就意识到,可能 2025 年不会那么顺利。
所以从 DeepSeek 开始,我就开始作为一名内容创作者,记录自己对于 AI 的发展、对于这个时代的看法和一些思考。
果不其然,2025 年的上半年其实还算不激烈,但下半年基本上是全面爆发。
2025 年的 5 月份,腾讯云推出了 CodeBuddy 这款 VS Code 插件。它可以辅助大家进行编程,当时给我一种耳目一新的感觉。
当时我还去写了这款插件的测评,并录制了视频进行演示说明。当天,我就获得了优质文章的奖励和认可。
进入 6 月份,我接触了字节跳动的 Trae 这款 AI IDE,并且开始使用 Trae 的国际版进行 vibe coding。
这是我 AI 编程的开始。
随后七八月份,腾讯云推出了 CodeBuddy 这款 IDE。
从五月份的 VS Code 插件到七八月份的 CodeBuddy IDE,腾讯云也一直在打造自己的编程工具。当时那段时间,邀请码可谓是一码难求啊。
然后,随着进入 2025 年的年末,Anthropic 的 Claude Code、ChatGPT 的 CodeX 相继成为开发者的主流选择。
并且因为用量的原因,智谱的套餐也逐渐火了起来,成为搭配 Claude Code 编程的一个不错的模型选择。我自己现在也一直在使用。
当然,这只是我凭借自己的回忆和经历,大概回顾了 2025 年我对于 AI 的一些经历,以及我使用的一些工具。
从 DeepSeek 到 CodeBuddy,从 Trae 到 Cursor,再到 Claude Code,再到 CodeX,它们之间的竞争从来没有停止过。
现在局面逐渐稳定了下来。国内的话,基本上就是 Trae 和 CodeBuddy:一个是字节的,一个是腾讯的。
然后大部分开发者的话,可能还会选择 Claude Code 和 CodeX,Coding的效果会更好一些。
我清晰地记得,2025年的4月份,我第一次听说 Claude 这款模型并登录使用。
当时的模型还是 Claude 3.5,但就给我一种非常惊艳的感觉。后来逐渐发布了 4.0、4.5、4.6,Claude 也逐渐被更多的人所知道。
到了 2025 年的 4 月份,我记得当时最火的文章就是和 MCP 相关的。
因为那个时候 Anthropic 刚刚推出了 MCP 这样的规范,腾讯的一些社区就开始搭建 MCP 的生态。一些博主也开始写 MCP 怎么样去接入一些平台(比如接入微信读书,以及接入一些常见的工具等)。我自己也写了一些类似的文章,所以当时的印象比较深刻。
然后就是 2025 年的 10 月份,Anthropic 推出了 Skill。Skill 从那个时候开始就步步高升,一直到 2025 年的年末,基本上热度都非常高,写的人越来越多,用的人也越来越多。支持 Skill IDE 的工具也越来越多。
这个时代不变就会被淘汰。
所以当 MCP 出现的时候,一些常用的 IDE 接入了 MCP;当 Skill 出现的时候,一些常用的工具又接入了 Skill。随着技术的不断发展,产品本身也在不断地进行更新。
2.关于AI产品
2025 年的产品层出不穷,但一些产品宁愿花钱进行广告和推销,也不愿意在提升用户体验和产品质量下功夫。😔所以我们在选择原产品的时候,还是要慎重一些。
比较火爆的就是 Coding 类的 Agent 产品,也就是用于编程的工具。
其实在 2025 年 DeepSeek 出现的那段时间,Cursor 的用户数量应该是相当多的。后来随着 Trae 以及 CodeBuddy 等相关编程 Agent 和编程 IDE 的上线,虽然转移了一部分初学者的用户,但很多的开发者还是选择留在 Cursor。
直到 Claude Code 和 CodeX 的出现,局面发生了变化:
- 它们形成了更强的 Agent 优势
- Cursor 的用户开始大量流失
- 越来越多的开发者转向了 Claude Code 和 CodeX,使用 Cursor 的人也越来越少
2025年,我付费使用过的产品有很多,比如:
- Get 笔记
- ListenHub
- Youmind
- dessix笔记
如果说是免费的工具的话,腾讯的ima知识库也是不错的选择
但是,随着新鲜感的减弱,以及自己在试用过程中的一些探索和思考吧,我和一些产品就渐行渐远了。比如我是 2025 年 11 月份开始正式订阅使用 Youmind 这款产品的。
刚开始的时候,为了获取用户,他们提供邀请奖励:
- 你邀请的人数越多,获得的积分就越多
- 但是到后面,拿到的积分越来越少
并且我当时使用 Youmind,主要是辅助自己进行公众号的创作。因为圈子里面每天发生的事情有很多,我感兴趣的东西也有很多,而使用传统的方式虽然也能进行创作,但是感觉比较花费时间。
所以 YouMind 就是帮助我进行创作,主要是进行绘图。当时那段时间我非常喜欢 YouMind 的绘图功能。
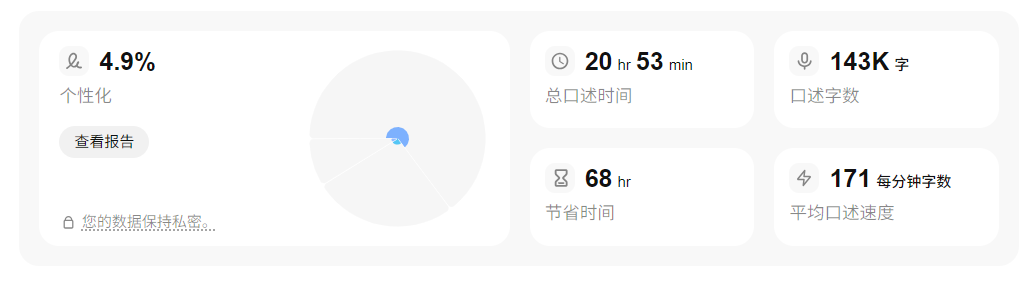
但是后来有了 Typeless 语音输入法,我非常喜欢它,并进行了订阅。
Typeless 的出现让我进行内容创作的效率大大增加。使用语音输入的方式,再加上我自己的个人字典,使得它的识别率、输出效果以及准确率都非常高,大大提升了我的创作效率。
所以我基本上就很少使用 YouMind 这款产品了。
当时那段时间,我还向身边的朋友推荐了这款产品,也写了不少文章进行自发推荐。
因为当时我真的很喜欢这款产品,再加上我是一个深度的内容创作者,所以基本上每天都在使用。
当时我推荐的时候,身边有一些朋友说,YouMind、Lovart 这款产品都是接了一些大厂的 API,做了一个第三方的平台罢了。甚至有人说,YouMind 就是用 AI 产生各种“垃圾”:
- AI 生成文章
- AI 生成 PPT
- AI 生成视频
- AI 生成图片
- AI 生成网页
等等等等。
当时那段时间,我还沉浸在使用 Youmind 的快感之中,认为接触 AI 让我的创作效率大幅度提升。所以当时那段时间,我的相当一部分文章都是使用 AI 辅助创作的。所以并没有把老师的话当回事。
但是用了一个多月之后,我发现我自己的创作热情变得逐渐冷却。
因为那段时间,我的大部分文章都是借助 Youmind 里面的模型帮我写的。我只是提供了一个素材或者说时间,让它帮我辅助创作,但文章的主题其实还是模型写的。我越来越觉得自己离创作的初心越来越远。加上当时 Typeless 的出现,后面我直接舍弃了 Youmind,开始使用 Typeless 进行自己的语音输入。
基本上文章里的所有观点全部都是自己的,一改之前使用模型进行创作的方式。我的成就感和获得感也大幅度提升。
现在互联网上,2025 年有一个热词叫做 AI Slop,说的就是使用 AI 工具去生产各种垃圾内容,然后发到社交平台。现在回想起来,那段时间我是用 YouMind 进行内容创作的。
那段时间,其实我觉得就是slop,我认为作为一个内容创作者,如果你写的文章自己都不想读个五六七八遍,那么就不要发出去。
否则,这不仅会影响大家的注意力,还在耗费、浪费读者的时间,这种行为相当于“谋财害命”。
当然不可否认,YouMind 对于部分用户还是很好用的。可能有一些资深的内容创作者是利用 YouMind 对文章内容进行打磨,不断提升文章质量,这种也算是用好了这款工具吧。但我认为我自己的使用方式很不合格,产生了堆积如山的 AI Slop。
当然,我身边的朋友反馈用 YouMind 在辅助硕士论文、本科毕业论文以及数学论文撰写上面,依然是发挥了很不错的作用,效果非常的棒。
这也因人而异。但是自此开始,我自己也不再使用这款产品了。
现在我的内容创作流程就是 Obsidian 加 Typeless 语音输入,创作效率也提升了。文章的观点基本上都是自己用嘴说的。
其实文章流量一般,但当我的文章真正发出去的那一刻,我的内心仍然是有成就感的;当我的文章被认可的那一刻,我的内心依然是有自豪感的。
至于其他的几款工具:dessix,listenhub,以及get笔记,typeless都是我长期使用的,尤其是 Typeless,对于少数派里面的用户来说,很多都是资深的内容创作者。我相信 Typeless 这样的工具能够大大地提升你的创作效率,以及你和大模型问答的效率;
因为和它模型问答的时候,大段大段的内容进行输入。而且它本来输入的内容都是结构化的语言,正好是大模型最喜欢的语言。
之前我们只能自己打字,人脑的带宽是有限的。Typeless 这种非常强大的语言输入工具的出现,大大提升了我们的输入带宽,进一步提高了我们的效率。
这款产品我非常推荐(edu邮箱申请五折优惠),下面是我的使用记录:
在内容获取方面,浏览器是一个网络的入口。
在 2026 年的 3 月份,也就是前段时间,一款名字叫做 Tabbit 的 AI 浏览器走入大众视野。从它开始公测的第一天,我就开始使用直到现在。
现在我已经是该 AI 浏览器的深度用户,它里面的一些功能和体验设计得都很不错,在这里我也非常推荐。快捷指令、脚本以及智能代理产品的很多设计细节,都给我一种眼前一亮的感觉。
3.知识管理
2025年6月,我开始正式转战 Obsidian。
文章最开头也说过,我最开始深入地理解 Obsidian,就是通过“西郊次生林”这个博主的一些文章,也是通过它认识了“少数派”这个社区。
2025年6月之前,我主要使用的工具是 Typora 编辑器。这是一款非常老牌的编辑器。主要支持 Markdown 语言,功能也相对比较完善。
其实,人开始使用一个工具总会有一些理由。
我使用 Typora 已经很长时间了,所以虽然看到不少用户和身边的朋友都给我推荐 Obsidian 的强大,但我一直没有使用。直到我发现了一款插件NoteToMP(付费),它可以直接把本地的 Markdown 笔记发送到公众号的草稿箱。
相较于我之前写公众号、发公众号的方式,这个插件大大提高了效率。也是因为这个插件,从某种程度上加快了我开始使用 Obsidian 的步伐。
自从 2025 年 6 月开始正式深度使用 Obsidian 之后,它就成为了我笔记软件里的主力,基本上所有的文章创作都在这个工具下进行。
再加上前段时间很火的一个插件叫做 Claudian,基本上让 Obsidian 成为了无敌般的存在。搭配起强大的插件系统和用户生态,Obsidian 在AI时代再一次伟大起来。
2025年的年末,我关注的一些博主以及加入的一些社群,很多老师都在给我推荐 Readwise Reader 这款阅读器。其实很早之前,我就在网络上见人推荐过这款工具,但当时并没有去使用。
直到 2025 年年末,随着我喜欢的老师和博主都在疯狂地给我安利,我最终还是开始安装并使用了它。到现在不到三个月的时间,Readwise Reader 已经成为了我的信息搜集器。无论是我订阅的一些邮件、播客,以及阅读的一些文章,全部都在这款稍后读的工具里面。
从最开始很不习惯使用,到现在爱不释手,中间确实经历了一些过程。但好在我没有错过它,最终还是成为了订阅用户,并且现在的深度使用感觉非常不错。(搭配博主:潦草学者,的小工具,实现了直接把公众号的文章转发到 Readwise Reader 阅读器的跨越,这款小工具用起来也相当不错)
其次,在 2025 年的暑假,我受身边一些朋友的邀请,去小宇宙上面录制了一期节目。
在这之前,我从来不知道这个平台,也并不了解播客是什么。但到现在,我也成为了小宇宙的深度用户。小宇宙已经成为我获取信息的一个重要来源,里面的内容质量普遍很高。小宇宙的用户呈现出高学历、高线城市的集中特征。年轻人偏多,而且质量都很不错。上面推荐的 Get 笔记可以针对小宇宙进行分析,listenhub 也是一款制作播客的工具。

但是即使如此,我还是看到了一些不一样的声音。
下面这篇文章是一位博主写的,这位博主的 ID 是“潦草学者”。他写了一篇文章,题目是《AI 时代,我的知识管理系统》,2025 年版本。这篇文章应该也是少数派上面的文章。
我觉得写得很不错,但是也有一些人说:知识管理有必要这么复杂吗?
我觉得 AI 时代,知识管理这件事情反而变得更加重要起来。
因为我们用的是一样的模型,如果我们使用一样的提示词,那么大模型的回复也不会有什么太大的区别。
而我们所搭建的知识管理系统,实际上,如果我们想要更大程度地让大模型为我所用、从大模型身上获取更大的收获,那么知识管理系统就显得无比重要了。因为在 AI 时代:
- 我们所搭建的知识管理系统
- 我们所写下的每一份 Markdown 笔记
这些实际上都可以作为和大模型交互的 Personal Context(也就是个人上下文)。通过这些东西,大模型能够更好地了解我们自己。这也是为什么 AI 时代,知识管理、知识库等移动产品会再度火爆起来。
为什么有些人用大模型可以获得很好的效果,但有些人却不行?
其原因在于:
- 有些用户积累了大量的 Personal Context(个人上下文)
- 而另一些用户只是简单地描述问题,没有给大模型提供任何语料和背景
大模型如果无法了解你,回答的质量就会显得很一般。这也是为什么同样的模型,由不同的人使用会有截然不同的效果,Personal Context 是一个非常重要的原因。
至于上面这位网友所说的“知识管理有必要这么复杂吗”,我认为因人而异。
有些人喜欢 All in One,但有些人喜欢“重器轻用”,即利用每个工具最擅长的部分,尽可能发挥它的作用。别人选择多款工具,也是为了利用各家所长,我认为并没有什么不妥。
人与人之间因为认知水平、信息获取方式以及接触内容等诸多差异,对于知识管理和信息管理的认识是不一样的,这也就造成了知识管理系统的差异。
关于这一点,我们只需要按照自己的使用习惯去操作就可以了:
- 没必要刻意模仿别人,适合自己的就是最好的。
- 我们自己就是最了解自己的那个人。
- 只需要搭建属于自己的系统,做到为我所用,我觉得就可以了。
至于其他人的系统,我们更多是以学习的态度去阅读。如果能从中有所发现、有所获益,那就再好不过了。
4.总结
在 AI 的时代,大模型的出现好像为这个世界的发展按下了加速键。在 AI 时代,我们每天接收了大量的信息,阅读了大量的内容。我认为最重要的是要有自己的看法和思考,形成自己的判断能力,而不是人云亦云。
在 2025 年,回望这一年所走过的路,我对”工具”与”人”的关系有了更深的理解。
模型的能力在飞速地增长迭代,但真正决定我们能从 AI 身上获取到价值的,从来不是模型本身,而是我们自己。
AI 时代每天都有很多热点可以让我们去追,但如果我们没有自己的判断力,没有自己的思考,那么我们很容易身心俱疲;
因此,在日常生活中,我们需要:
- 选择一些高质量的信息源
- 阅读一些高质量的内容
- 记录自己的想法和思考
- 形成自己的判断力和甄别能力
- 打造自己的 Personal Context,让顶级的模型真正地为我们所用
AI 的技术是加速器,但方向盘永远掌握在我们自己的手中。
愿我们都能在和 AI 共处的日子里,保持内心的清醒、独立和清醒。做 AI 的主人,而不是它的附庸
]]>